2020-Self-supervised Learning for Large-scale Item Recommendations
Motivation
长尾的item没法得到充分训练
方法
自监督学习框架
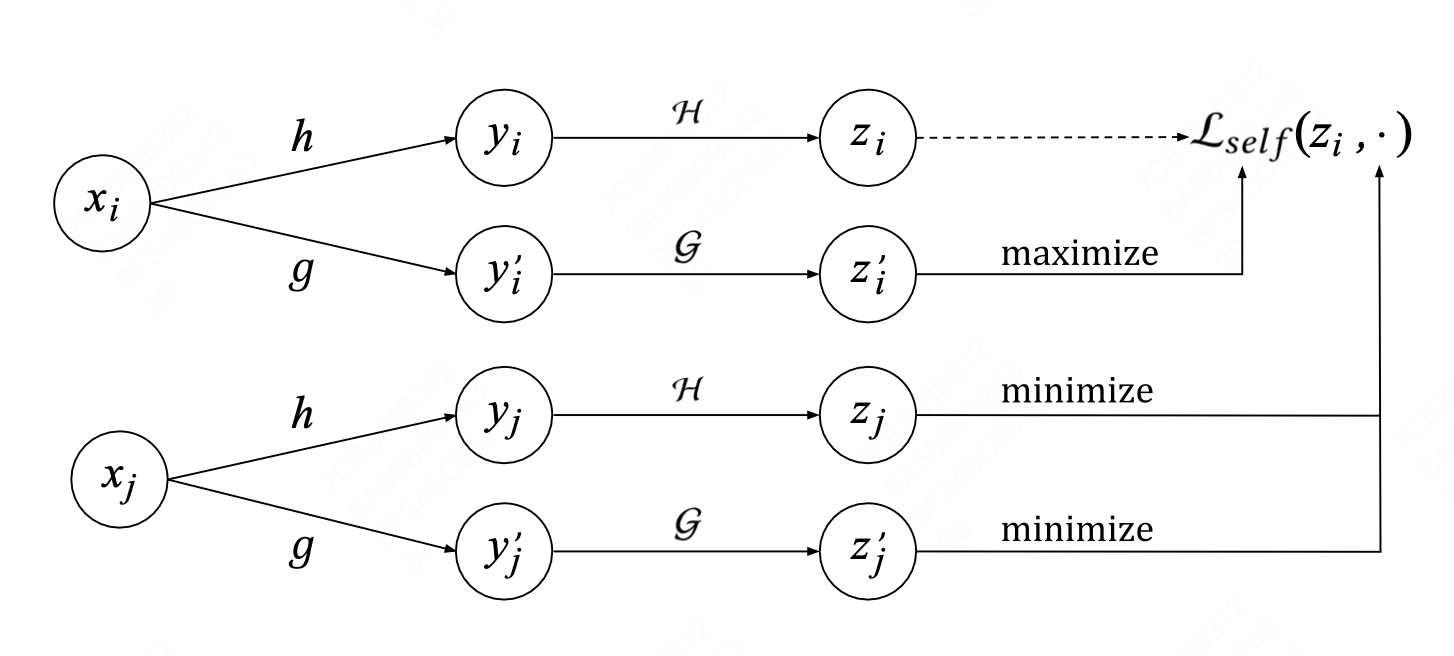
- 如上图,首先通过两种数据增强的方式将输入item特征\(x_i\)分别转化为\(y_i\)和\(y_{i}'\)
- 通过模型将数据增强后的\(y_i\)和\(y_{i}'\)分别编码为\(z_i\)和\(z_{i}'\)
- \((z_i,z_{i}')\)作为正样本对,\((z_i,z_{j}')\)作为样本对,通过损失函数使同一个item的embedding越接近,不同item的embedding远离
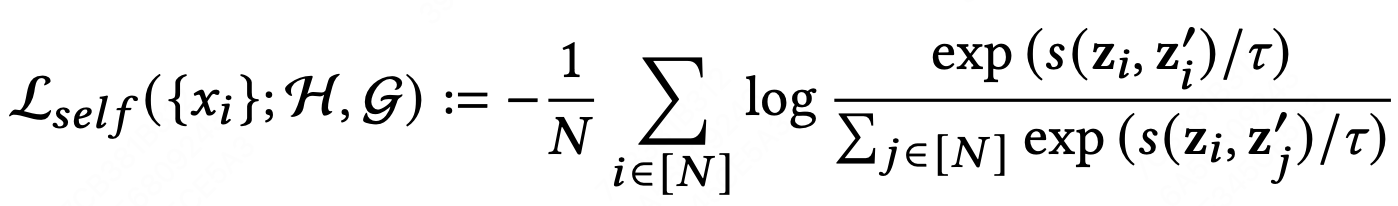
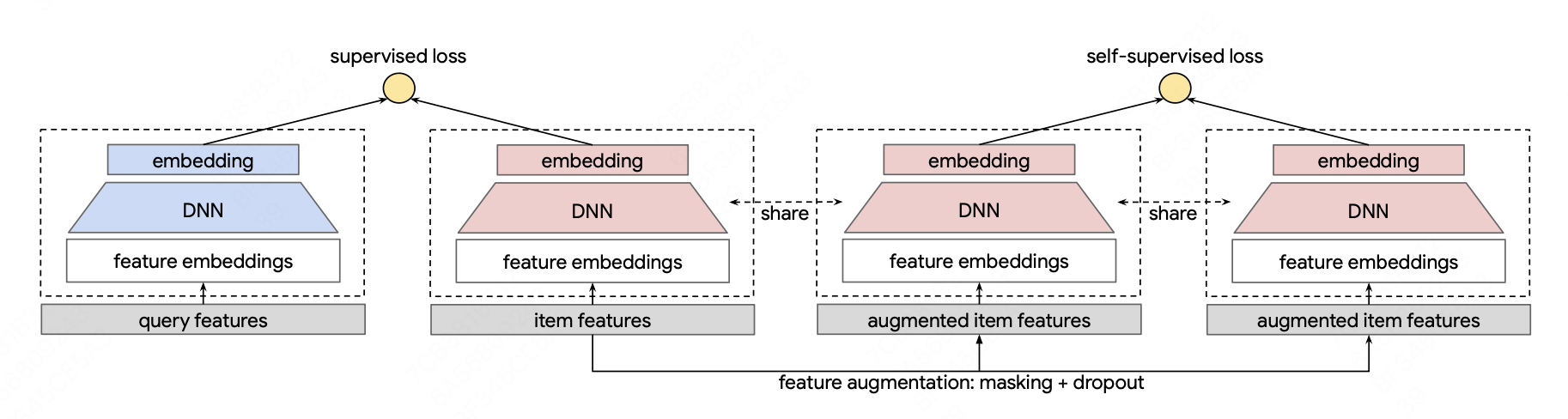
two-stage数据增强
- Dropout: 对multi-hot特征随机dropout一部分特征
- Mask:通过mask的方式掩饰掉一部分特征后学习向量表示
RFM(Random Feature Masking):随机mask一部分特征,两个data aug特征为互斥子集 存在的问题:使用随机的方式有可能两个子集中存在相关性很强的特征
CFM(Correlated Feature Masking):通过离线的互信息计算各个特征之间的相关性,先随机选择一个特征,同时mask和他相关性最高的topk特征
联合训练
Heterogeneous Sample Distributions
训练样本是幂律分布,直接训练会使自监督损失偏向于头部item,用于训练自监督loss的训练样本经过均匀采样
原文: In practice, we find using the heterogeneous distributions for main and ssl tasks is critical for SSL to achieve superior performance.
总结
- 提出一个双塔模型自监督学习框架,优化推荐系统中长尾item学习不充分的问题
- 使用CFM方法做数据增强
This post is licensed under CC BY 4.0 by the author.