2020-Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
挑战
在推荐系统场景下,用户的历史行为信息有着至关重要的作用,但是长序列建模对计算资源是一个挑战 SIM模型提出一种基于检索的用户行为兴趣CTR模型
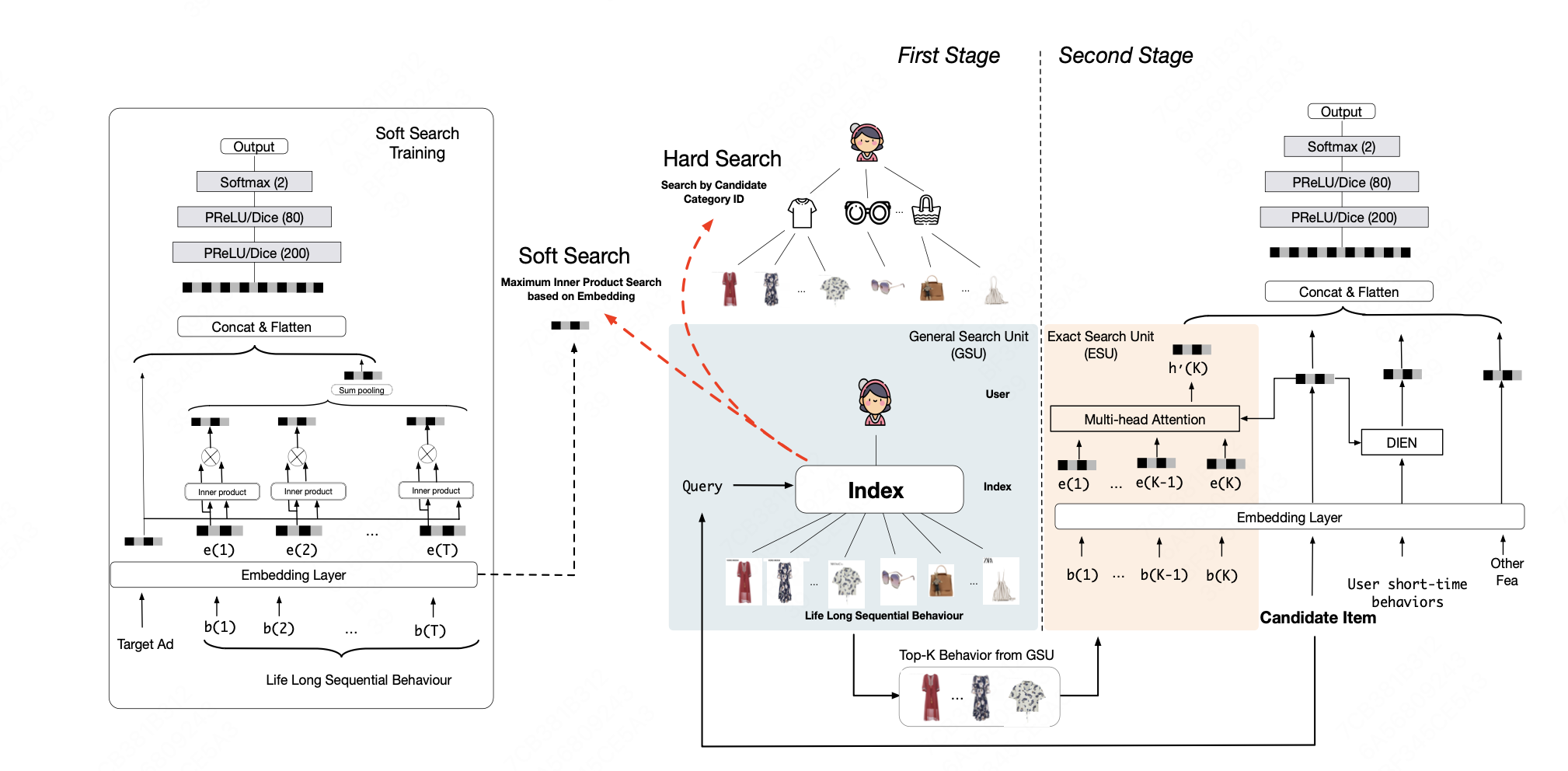
SIM包含两级检索模块GSU(General Search Unit,通用搜索单元)和ESU(Extract Search Unit,精准搜索单元)
- GSU通过从原始用户行为中搜索Top-K相关的用户子序列行为,同时K比原始用户行为小几个数量级(从用户丰富的长期历史行为队列中挖掘用户有价值的兴趣点)
- ESU负责对筛选后的行为序列进行深度学习建模,计算CTR。
GSU
GSU包括两种方案,hard-search和soft-search
- hard-search是无参数的,直接从用户历史行为中筛选目标相同的item
- soft-search根据目标embedding和行为embedding的内积进行相似性检索 给定用户的行为序列\(B=(b_{1},b_{2}...b_{T})\),GSU对于每一个用户行为计算一个相关性得分\(r_{i}\),根据\(r_{i}\)选择topK用户行为
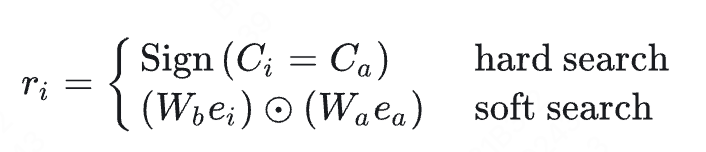
但是由于长期兴趣和短期兴趣的数据分布存在差异,不能直接采用已经学习充分的短期兴趣模型向量来进行相似用户行为计算。
对于soft-search,GSU采用了一个辅助CTR 任务来学习长期数据和候选广告之间的相关性
ESU
前一阶段,筛选出了用户topk相关的历史行为,ESU用于提取精准的用户兴趣。
- 首先,由于超长用户行为序列时间跨度长,因此需要在历史行为embedding中引入时间状态属性
- 通过多头注意力机制提取特征
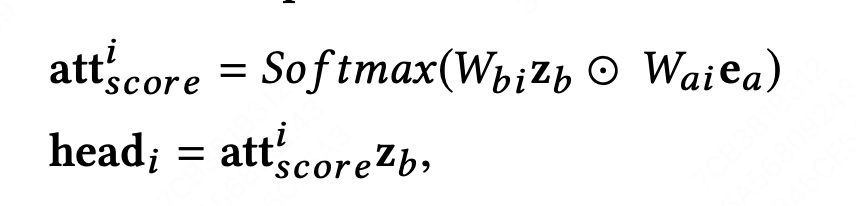
在线服务
考虑到离线效果提升和线上资源消耗,阿里巴巴线上实际使用的是hard-search方法,对于hard-search,用户行为可以直接按照类别进行组织并建立好离线索引
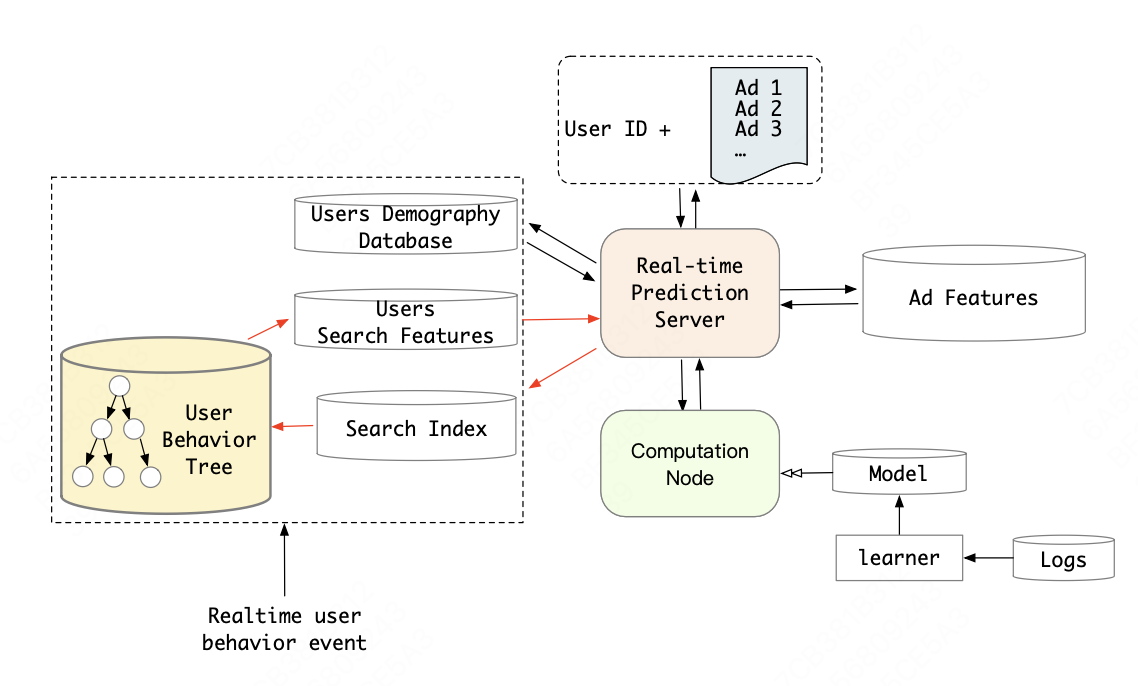
用户行为树UBT采用Key-Key-Value数据结构来进行存储。
第一级key是用户ID,第二级key 是叶子行为所属的类目。采用分布式部署的方式处理UBT数据使得它能服务大规模的在线流量请求,并采用广告类目作为hard-search检索 query。
GSU模块使原始用户行为长度从上万数量级降低到百级
This post is licensed under CC BY 4.0 by the author.