2019-Personalized Re-ranking for Recommendation
问题建模
一般情况下,LTR优化问题被建模为:
\[\mathcal{L} = \sum_{r\in\mathcal{R} } \mathcal{l}({y_{i},P(y_{i}|\pmb{x}_{i};\theta )|i\in \mathcal{I}_{r}})\]- $\mathcal{R}$:用户请求(request)集合
- $\mathcal {I}_{r}$表示请求 $r\in\mathcal{R}$的候选item集合
- $\pmb{x}_{i}$ 表示item $i$的特征向量
- $y_{i}$ 表示item $i$ 的label(eg.是否点击)
- $P(y_{i}\mid \pmb{x}_{i};\theta)$ 表示在排序模型参数是$\theta$的情况下,item $i$ 被点击的概率
存在的问题:忽略了两方面的重要信息
- item-pair之间的共同作用
- items和users之间的相互关联
对于item-pairs之间的共同作用,可以通过现有LTR模型提供的初始list$S_{r}=[i_1…i_n]$学习到,对于items和users之间的的关联关系,本文引入一个个性化的矩阵$\pmb{PV}$来编码用户和items之间的关系 本文的问题建模为
\[\mathcal{L} = \sum_{r\in\mathcal{R} } \mathcal{l}({y_{i},P(y_{i}|\pmb{X},\pmb{PV};\hat{\theta} )|i\in \mathcal{S}_{r}})\]$\mathcal{S}_{r}$表示排序模型提供的初始item list $\pmb{X}$表示列表中所有item的特征矩阵 $\hat{\theta}$表示rerank model参数
模型结构
模型结构主要包括三个部分,输入层(Input Layer)、编码层(Encoder Layer)和输出层(Output Layer)
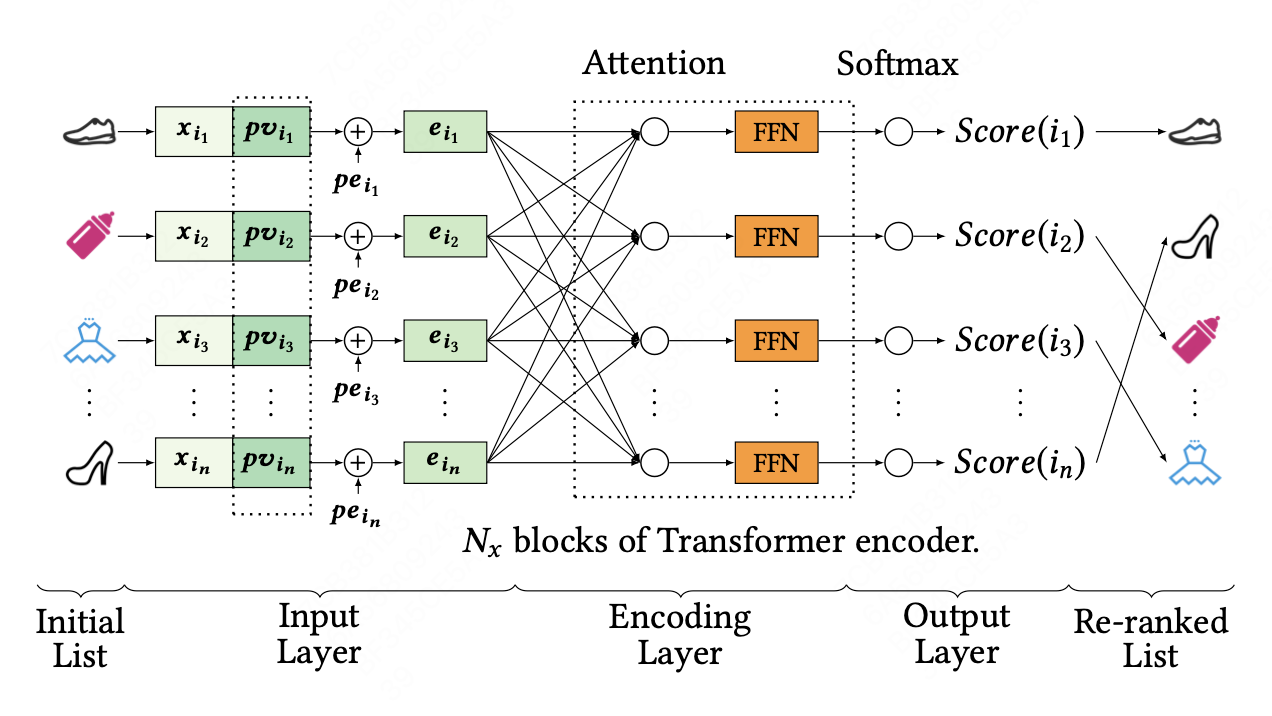
Input Layer
模型初始输入是由排序模型提供的list $S_{r}=[i_1…i_n]$,初始特征矩阵$\pmb{X}\in\mathbb{R} ^{n\times d^{feature}}$,$\pmb{x}_{i}$是item $i$的特征向量。
首先,将item特征向量矩阵与PV向量,$PV\in\mathbb{R} ^{n\times d^{pv}}$,拼接在一起,构成
\[E^{'} =\begin{bmatrix}\pmb{x_{i_{1}}};\pmb{pv_{i_{1}}}\\\pmb{x_{i_{2}}};\pmb{pv_{i_{2}}}\\...\\\pmb{x_{i_{n}}};\pmb{pv_{i_{n}}}\end{bmatrix}\]$E^{‘} \in\mathbb{R} ^{n\times d^{feature+pv}}$,然后在输入矩阵向量中插入可学习的位置编码,$PE \in\mathbb{R} ^{n\times d^{feature+pv}}$
\[E^{''} =\begin{bmatrix}\pmb{x_{i_{1}}};\pmb{pv_{i_{1}}} \\\pmb{x_{i_{2}}};\pmb{pv_{i_{2}}}\\...\\\pmb{x_{i_{n}}};\pmb{pv_{i_{n}}}\end{bmatrix} + \begin{bmatrix}\pmb{pe_{i_{1}}}\\\pmb{pe_{i_{2}}}\\...\\\pmb{pe_{i_{n}}}\end{bmatrix}\]最后,使用一层前馈网络将$E^{‘’}\in \mathbb{R} ^{n\times(d_{feature} +d_{pv} )} $转换成 $E\in \mathbb{R} ^{n\times d} $
\[E = E^{''}W^{E} +\pmb b^{E}\]$d$对应编码层的输入向量维度
Encoder Layer

Attention模块
\[Attention(\pmb{Q},\pmb{K},\pmb{V} ) = softmax(\frac{\pmb{QK^{T} } }{\sqrt{d} } )\pmb{V}\]为了提取更丰富的特征,使用多头注意力机制
\[S^{'}=MH(\pmb{E})=Concat(head_{1},head_{2}...head_{h})W_{o}\] \[head_{i}=Attention(E\pmb{W}^{Q}\pmb{W}^{K}\pmb{W}^{V})\]$\pmb{W}^{Q},\pmb{W}^{K},\pmb{W}^{V}\in\mathbb{R} ^{d\times d }$,$\pmb{W}^{O}\in\mathbb{R} ^{hd\times d }$,$h$是head数
注意力机制后跟随一个前馈网络通过多个注意力模块堆叠提取高阶特征
Output Layer
输出模块包括一个线性变换层和一个softmax层,softmax层输出每个item的模型预估点击概率$P(y_{i}|\pmb{X},\pmb{PV};\hat{\theta})$,此处表示为$score(i)$
\[score(i) = softmax(F^{N_{x}}W^{F}+b^{F}),i\in \mathcal{S} _{r}\]其中$F^{N_{x}}$是经过$N$个tranformer模块编码后的特征向量,$W^{F}$和$b^{F}$都是可学习参数。
Personalized Module
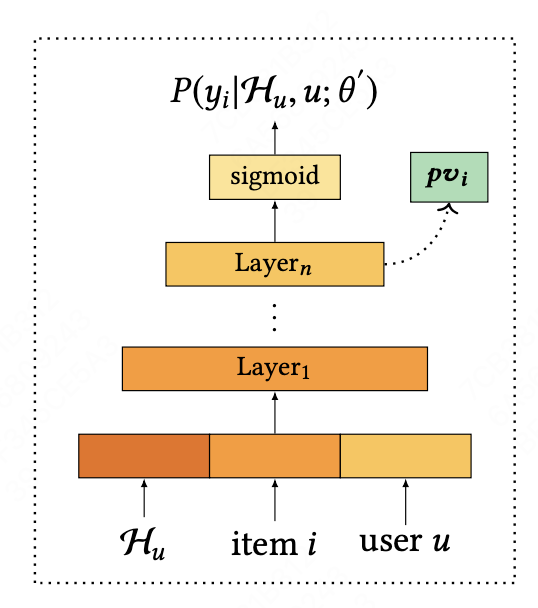
输入模块中的个性化向量矩阵由预训练模型中获得,预训练模型可以是FM、DeepFM,DCN和FNN等网络结构,输入特征向量是item特征和user属性+历史行为特征,输出模块通过Sigmoid函数预估用户对商品的点击概率\(P(y_{i}|\mathcal{H}_{u},u;\theta')\),其中$\mathcal{H}_{u}$ 表示用户的历史行为,$\theta’$为预训练模型参数 模型训练损失函数表示为
\[\mathcal{L} = \sum_{i\in\mathcal{D} } (y_{i}log( P(y_{i}|\mathcal{H} _{u} ,u;\theta^{'} ))+(1-y_{i})log( 1-P((y_{i})|\mathcal{H} _{u} ,u;\theta^{'} )))\]其中,$\mathcal{D}$表示给用户展示过的item集合,sigmoid层前一层的隐向量作为$pv_{i}$应用到rerank模型
Pei C, Zhang Y, Zhang Y, et al. Personalized re-ranking for recommendation[C]//Proceedings of the 13th ACM conference on recommender systems. 2019: 3-11.