2022-PEAR-Personalized Re-ranking with Contextualized Transformer for Recommendation
Motivation
- 从list-wise角度捕捉item之间的相互影响
- 先前的工作比如GlobalRank和 DLCM使用RNN编码序列,但是RNN捕捉pairwise信息的能力有限,PRM and SetRank使用了transformer结构,但是没有充分利用个性化信息(user特征)
- 本文提出PEAR模型结构,从feature-level和item-level进行信息交互,使用多目标任务结构预测item的预估分和预测用户对list的满意度
Method
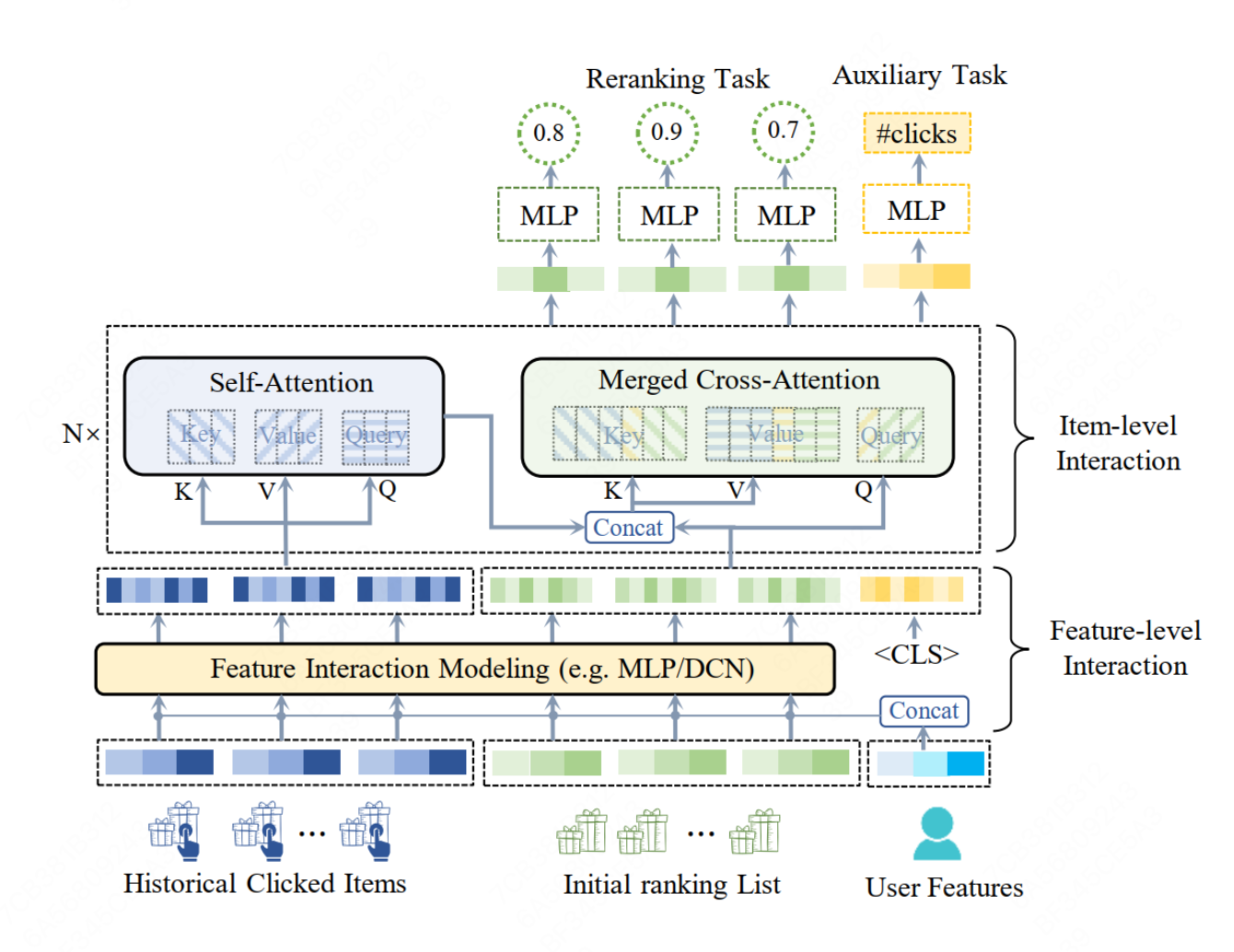
Feature-Level Interaction
模型的输入分为三个部分:用户历史行为序列\(B=[b_{1},b_{2}...b_{n}]\),初始化item序列\(S=[s_{1},s_{2}...s_{n}]\),用户特征
- 将历史行为序列中的item特征编码和user特征编码拼接在一起,形成特征表示矩阵 通过两层MLP对user特征和item特征进行融合
- 为了解决list-level的任务,受到bert的启发,添加一个参数可学习的CLS token在初始化item序列编码的后边
Item-level Interaction
本文中提出的item-level的交互结构,不仅仅能够学习用户历史行为和初始化item两个list内部的item特征交互,还能够学习list之间的特征交互,具体步骤:
- 首先,使用一个自注意力层编码用户的历史行为序列
- 使用一个self-attention子层和一个cross-attention子层,为了简化计算,本文将两个子层合并计算
Multi-task Training
单个item的损失函数:用户是否有点击目标item
\[L_{m} = \sum y_{t}log\hat{y_{t}} + (1-y_{t})log(1-\hat{y_{t}})\]序列整体损失函数:序列中是否包含正样本
\[L_{aux} = \sum y_{aux}log\hat{y_{aux}} + (1-y_{aux})log(1-\hat{y_{aux}})\] This post is licensed under CC BY 4.0 by the author.