2021-Contrastive Learning for Representation Degeneration Problem in Sequential Recommendation
Motivation
- 序列推荐场景中,模型生成的embedding会退化,导致不相似的item样本embedding很集中
- 现有对比学习,大多依赖于data-level的数据增强(cropping, masking, or reordering), 这种方法可能会破坏原数据中的语义关联
- 本文提出一种model-level的对比学习数据增强方式
- 矩阵A的秩等于它的非零奇异值的个数
- 如果奇异值主要集中在几个有限的元素上,并且有较少的奇异值远远大于其他的奇异值且奇异值比较集中的,则该矩阵可以近似看作低秩的,(https://zhuanlan.zhihu.com/p/148629967)
Method
序列编码作为用户表征
使用transformer编码用户序列,第t个位置的商品编码为item表征+位置编码 \(h_{t}^{0} = v_{t} + p_{t}\) 经过L个Transformer模块后,向量编码为\(H_{L} = [h_{0}^{L},h_{1}^{L}...h_{t}^{L}]\),其中\(h_{t}^{L}\)是序列整体表征
推荐学习
交叉熵损失函数优化推荐问题
对比正则项
在序列向量的计算中,embedding层和Transformer编码器中都有Dropout模块。使用不同的 Dropout 掩码将输入序列前向传递两次将生成两个不同的向量,它们在语义上相似但具有不同的特征。 在transformer的输入阶段,通过另一个mask获得\(h_{t}^{0}{'}\)
正采样
语义相似性。如果两个序列代表相同的用户偏好,那么很自然地推断出这两个序列包含相同的语义。
负采样
同一训练批次中的所有其他增强样本都被视为负样本,设训练批次为\(\mathcal{B}\),大小为\(|\mathcal{B}|\),数据增强后大小为\(2|\mathcal{B}|\),序列表示为 \(\{h_{1}',h_{1,s}',h_{2}',h_{2,s}'...h_{|\mathcal{B}|}',h_{|\mathcal{B}|,s}'\}\) 除了目标相同的序列是正样本对,其他都是负样本对 \(S^{-} = \{h_{2}',h_{2,s}'...h_{|\mathcal{B}|}',h_{|\mathcal{B}|,s}'\}\)
正则化目标
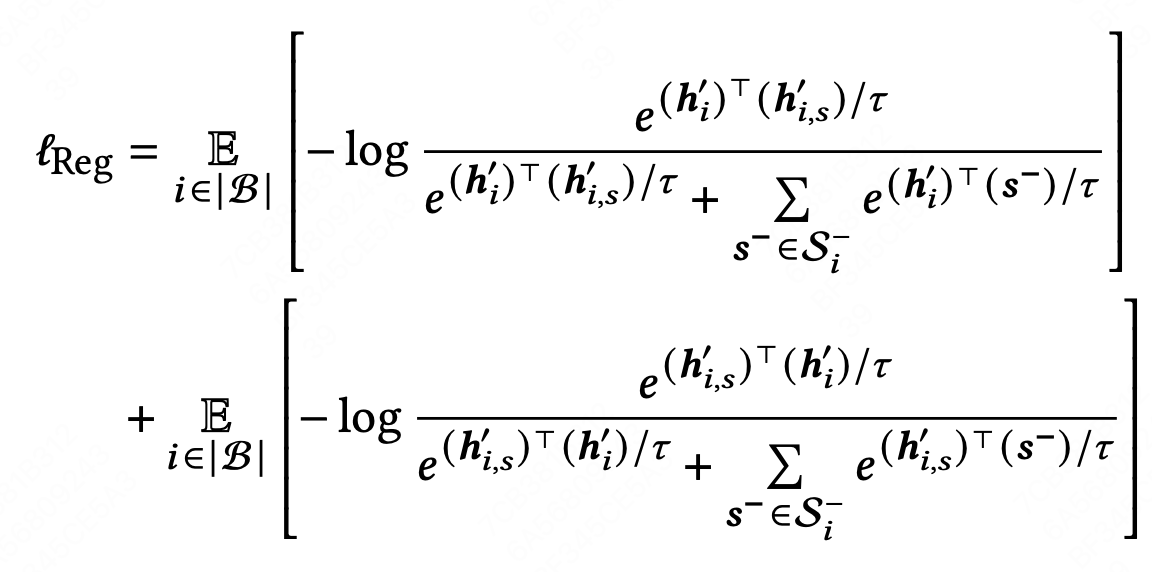
This post is licensed under CC BY 4.0 by the author.