BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
摘要
BERT是一个预训练模型,他利用无标签的文本数据做预训练,与其他语言模型不同的是,BERT在每一层都利用双向的文本信息。在预训练BERT模型的基础上,通过一个输出层的fine-tune可以在多个nlp应用领域获得sota效果。
具体介绍
作者认为,在之前的预训练模型中,比如GPT,单向信息的学习限制了模型的选择,每一个token只能利用之前的token信息。本文提出的预训练模型BERT:(Bidirectional Encoder Representations from Transformers),使用masked language model(MLM)双向学习token上下文信息,另外,引入next sentence prediction(NSP)学习文本对表示。
模型结构
BERT的模型结构使用的是一个多层堆叠的Transformer encoder结构 模型大小
| 表头 | Transformer Block | hidden size | head num | 总参数量 |
|---|---|---|---|---|
| BERT_BASE | 12 | 768 | 12 | 110M |
| BERT_LARGE | 24 | 1024 | 16 | 340M |
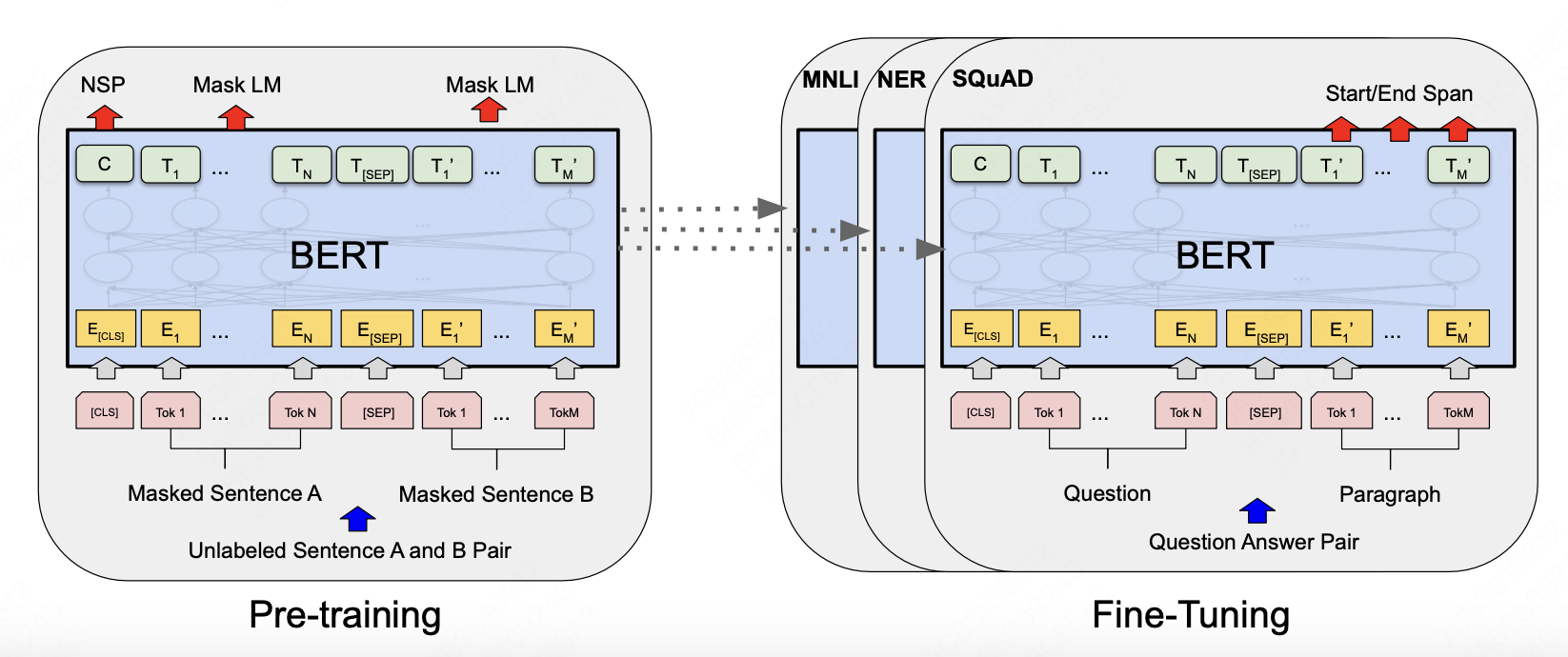
输入输出形式
BERT在多种下游任务上都具有很强的泛化性,模型的输入与输出需要适应不同任务的变化。他的输入有可能是一个单独的句子,也有可能是一对句子(eg.{question,answer})

输入输出的具体设计
- 首先,对于每个输入的句子的第一个token不再是句子第一个单词的token,而是[CLS]的token,用来表示分类任务,模型输出对应位置的表征用来解决分类任务
- 为了应对多个sentence输入的情况,本文提出了两种方式。第一,两个sentence中间放置一个[SEG]token作为分割,然后为每个token学习一个embedding来表示token输入句子A或者句子B
- 总之,对于一个给定的token,如上图所示,其表示向量为 \(token\ embedding + segment\ embedding + position\ embedding\)
预训练
BERT使用两个无监督任务来做与训练,不再使用从左到右或者从右到左的单向训练方式。
Task #1: Masked LM
为了能够利用双向语义信息来预训练模型,本文使用的方法是:随机使用[mask] token替换原句中15%token,然后预测这部分token对应的单词。 这样存在一个问题是在下游fine-tuning任务中,大概率是不存在[mask] token的。 所以在训练样本中随机选择的15%预测token中,80%替换为[mask] token,10%替换为随机token,10%仍然是真实token。
Task #2: Next Sentence Prediction (NSP)
在一些NLP任务中,比如问答系统(Question Answer,QA)或者自然语言推断(Natural Language Inference,NLI)中,模型需要学习两个句子之间的关系。 本文将句子之间关系学习的任务设计为一个分类任务。50%的情况下,A和B是真实的上下句关系,标记为正label,另外50%的情况下,B句从语料库中随机生成,标记为负label。使用前文中输入模块提到的[CLS]位置来学习这个分类任务。
Fine-tuning
在输出部分加入task-specific的output layer,使用有监督数据端到端训练,预训练模型的参数也会同时调整。
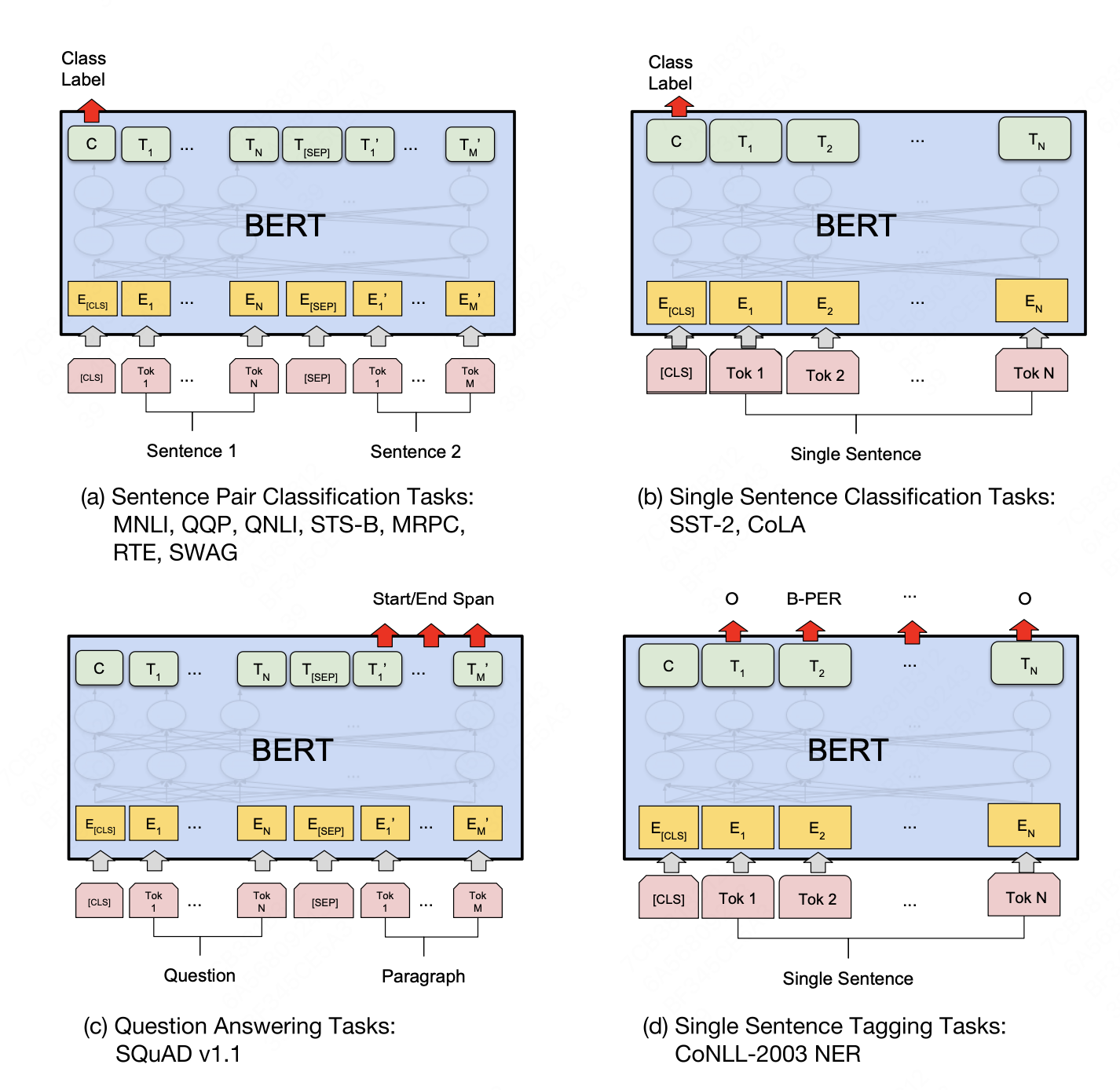
- Sentence Pair Classification Task,模型输入两个sentence,输出类别标签,比如判断第二个句子对第一个句子是赞臣/中立/反对态度,判断第二个句子是否与第一个句子语义相近,直接利用[CLS] token的hidden layer的output,接一个全连接层做分类任务
- Single Sentence Classification Task,输入一个sentence,输出句子的类别,同样使用[CLS] token的输出
- Question Answering Tasks,模型输入一个Question和一个Document,输出Question的答案在Document的什么位置。在fine-tune阶段学习两个vector ,start vector 和 end vector,维度等于BERT隐层输出维度,在document部分,每个token生成的向量与两个vector做内积,再通过softmax得到概率分布。
- Single Sentence Tagging Task,命名实体识别任务,比如句子中的人名、地点、时间等,和上一个任务类似token级的任务